

Data Modelling using JSON: JSON is short for JavaScript Object Notation. It is a human-readable text format and we use it to represent and transmit objects. The JSON structure is very popular and we apply it for data modeling in document databases and across many other technologies as well.
JSON Data Structure
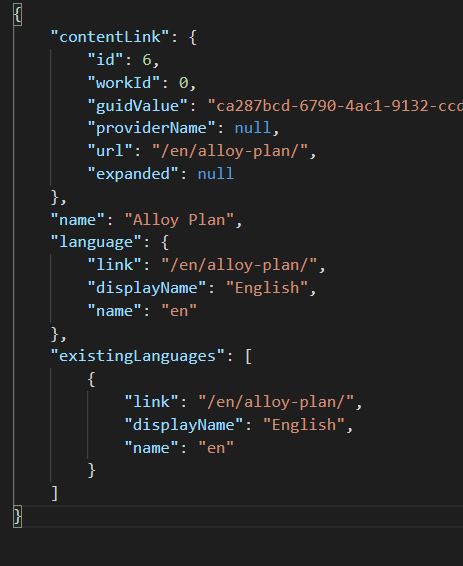
In the above figure, the JSON structure consists of a curly brace, and within these, we have what are essentially key and value pairs. Attribute values can be a string, a number, a boolean, a nested JSON object, or an array.
Technically speaking JSON has 3 main data Types:
- Primitive such as Boolean, String, Int, Double, etc.…
- Incomplete Information: Null, Missing.
- Composite: Object, Array, Multiset.
JSON Role in Modeling Data for Document Databases
The data model for document databases consists of a structured hierarchy. A document’s data may contain embedded documents. Each document has data that represent the attributes of an entity. We organized Documents into collections (equivalent to tables in a Relational database). For more info please check my previous article about NoSQL DB and Data Model.
Inside each document, there are attributes (fields). These attributes are in the format of key-value pairs.

Normalization vs Denormalization
When it comes to a relation database, it’s a fact that Normalization is the best practice approach to better maintain the data and avoid redundancy. Let’s take an example of page data in a CMS that needs to be stored in a relational database: Id, title, metadata, description, properties, subpages, date. In order to follow best practices, it is recommended to store related parts of data together in one table such as ID, Name, Date, Metadata, and Description. Obviously, we insert, update, or retrieve these parts of data together and the relation between them is one to one. For Page Properties or Subpages, we should create other tables and reference only the page ID with each page property or subpage:
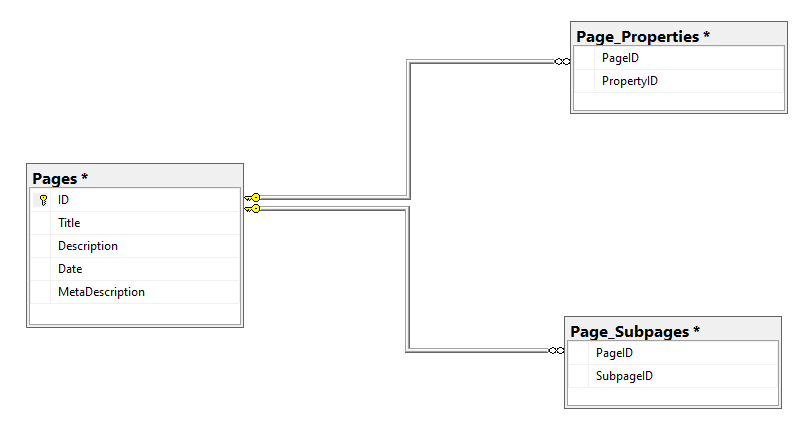
Contrarily, when it comes to non-relation databases (NoSQL) the denormalization approach is the best practice. Denormalization is the opposite of normalization. All related data for an entity is compressed into a single document in NoSQL databases.
Even, denormalization is used quite a lot in document databases, there will still be other documents related to each other. We can group them together in a “Unit” that varies from a non-relational database to another one. It could be a Collection in MongoDB or a Container in CosmosDB for example. So, the same example will be:
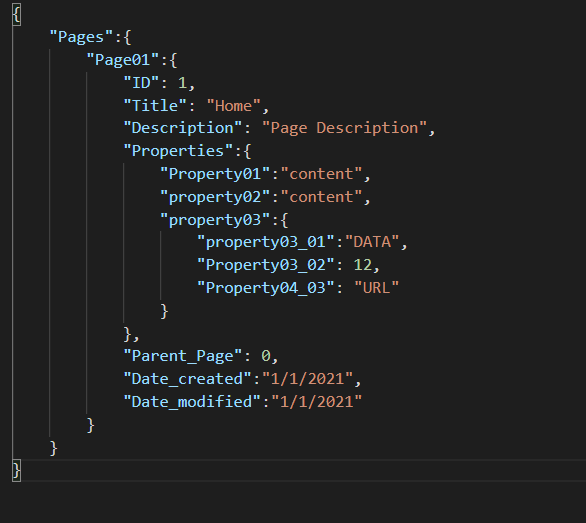
As we can see the document my have nested structures (complex) such as arrays and/or objects beside simple primitive fields. The name of this approach is “Nested Joins.”
Nested Joins vs Ordinary Joins

The conceptual view for an ordinary Join will look like this:

Based on that, the nested join approach makes it possible to embed all related data for an entity in one single document. Using the ordinary join approach will retrieve the entity (page) data each time along with each different property related to the page.
Which approach to follow: Normalization or Denormalization (Nested approach)?
Following the same example, let’s say we have pages and page properties. So, 2 related entities. Should these entities be represented in separated documents (normalization)? Or, should one of them to be nested within the second (Denormalization using Nested Join approach)?
First of all, in document databases, the optimal solution depends on the use case itself.
Use case analysis
It makes sense to group both entities using a nested approach if both are viewed together. In other words, if both entities should be retrieved in a single query. In our case, we retrieve a page with its properties. Thus, we can reduce the query processing time and this will improve the overall performance of the CMS and increase the user experience satisfaction. It makes also sense if both entities (page and its properties) are updated together because we will retrieve here 1 document instead of 2.
The opposite also applies. If no need to retrieve or update certain entities, it is better to split them using the normalization approach. This will enhance the integrity of the data and prevent redundancy.
Now, if you choose the nested approach, the next question will be which entity to be nested inside the second? This depends on the nature of the relation between them. In our case, we have Pages and Properties. The relation is one-to-many: One page may have one or more properties. Then it is obvious that we need to group the properties entities within the page and not the opposite.
The nested approach doesn’t make sense in case the relation between 2 entities is many to many. For example, Pages and subpages. A page may have 1 or more subpages and also the subpage may have 1 or more parent pages. Furthermore, no need to retrieve or update multiple pages at the same time. Then separating them is the best approach using the normalization approach.
Conclusion
Document in the context of document databases refers to values that are JSON documents. Modeling a non-relational database depends a lot on the use cases. In light of the usage, we can select either the denormalization or normalization approach for each group of entities.
Using a JSON data structure, every document will have a set of attributes. These attributes consist of keys and values. The type of values can be Basic such as string, number, or Boolean, or complex like array or object (embedded documents).
Feel free to leave a comment or to Contact Me for an open discussion!