

Data Model
A Data Model represents the framework of what the relationships are within a database. Building a data model is critical because it provides the structure of the information. The data itself will be stored, manipulated, and retrieved from within this framework on a database.
Understanding Data Models.
In order to better understand Data Models, there are 3 factors to consider:
- Conceptual view of data
Defining what exactly is the data that we need to represent, what each of the entities is, and what data we should store for each entity, and finally, how different entities are related to each other.
- Logical view of the data
Specifically, the data type to use in order to store the attributes for the entities such as strings, integers, double, float, etc…
- Physical storage of data
How data model will determine the physical storage of data.
Example:
We have an e-commerce website, we decide in the conceptual view, that we are going to store information about products, customers and we can have orders that can link products to customers. In the logical view, we may determine that a product’s name should be stored as a string while its price will be stored as a double value. For the physical storage, we may choose that order information and customer information should be placed together since they are accessed together.
Database Technologies
We apply data modeling for different categories of database technologies. In fact, databases can be broadly classified as relational databases and NoSQL (non-relational databases). Let’s first dig into RDBMS which makes use of the Relational Data Model.
Relational Data Model
Tables
We arrange data in this model in table format (rows and columns). Each row adheres to a schema. The schema defines the columns in each row, and the types of data in each column.
Example
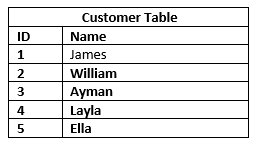
Following the same example of an e-commerce website, the above table represents information about customers. We represent each customer by a unique ID and a name. Each row has exactly 2 columns (unique ID of type number, and name of type string).
A customer has the ability to place orders. Following this example, we can store the order as an entity represented by a table.
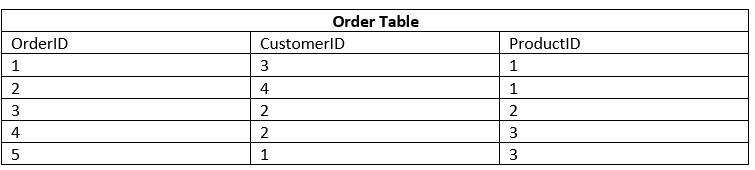
For each order, we store a unique ID, Customer ID (which can be repeated as one customer can do multiple orders) as well as the product ID which also can be repeated.
Normalization
One of the important properties of Relational Data Modeling is data normalization: Splitting information across different tables in order to avoid data redundancy.
If we look at the Order table, we will see that the customer is represented by its unique ID only without any other related data like a name. This splitting of information help reducing data redundancy. In other words, in order to know who is the customer who placed an order we just need to know his unique ID. By using it, we can retrieve all other information.
Constraints
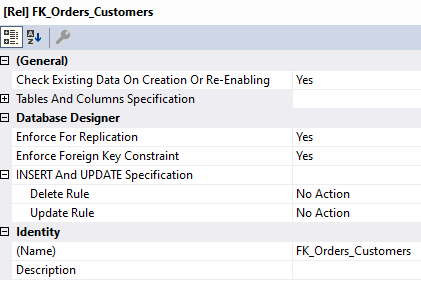
Yet, another important property is table constraints. For example, a Foreign Key represents a relation between a column in one table and the content of another table.

In the above diagram, we reference the Customer Primary Key (ID) as a Foreign Key in the Orders table (CustomerID). By applying this relation, we can impose several constraints to enhance data integrity as in the below figure:
Non-relational Data Modeling
Different from the Relational Data Model, there is a broad category of models that apply to the No-SQL databases (Non-relational databases). Among these models:
Graph Databases:
it models relationships between entities in the form of graphs. Its main goal is to emphasize relationships over entities. It uses Nodes and Edges. Nodes represent Entities while Edges represent the relationships between the nodes (entities). Graph model supports semantic queries to access information.
Object Databases
In this model, we record the information in a form similar to objects in a programming language. Also, we define entities using classes and we create an instance of these entities as an object. The target of Object Databases is to model data in a more closely way to how it is accessed in a programming language to overcome the RDBMS challenge which is Object-Relational Impedance Mismatch.
Key-value Databases
This is where document-oriented databases come into the picture and more specifically JSON Data format. Key-value databases have several implementations. Some of the commonly used document-oriented databases include Couchbase, MongoDB and hosting solutions on the cloud are available in the form of Azure’s Cosmos DB as well as DocumentDB on Amazon’s web services.
Wide Column Databases
As explained at the beginning of the article, relational databases make use of strictly defined schema that sets a fixed number of columns for each row. In case there is a need to add or remove columns this is considered as a major change and represents a challenge. Furthermore, because each row must have an identical number of columns, some of them have no value. In this case, a null value will be recorded for the corresponding empty column. But this in turn does end up occupying a lot of space. The Wide Column model comes to overcome these issues. By using a flexible schema, instead of altering a table to add or remove a column in the Relational model, we just need to add an additional row.
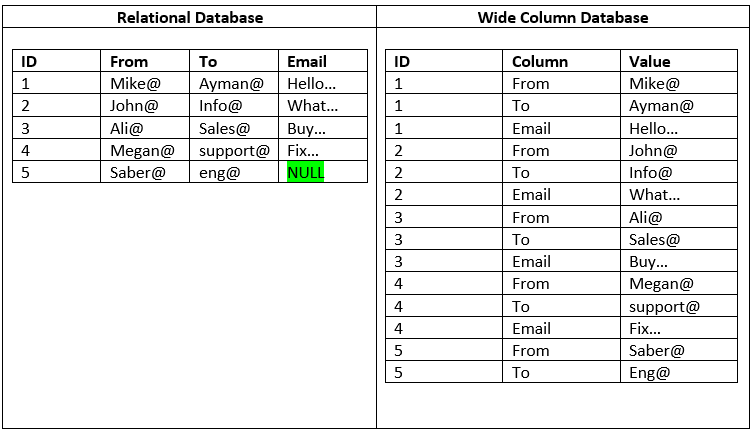
As in the above figure, in the Wide Column model, we don’t need to alter the table to add a new column. Rather just add the new column as an additional row. Also, we can see that in the relational database row #5 has a null value because the columns Email must exist for all rows. But in the Wide Column model, we don’t have the same case because there is no schema obligation to represent this missing information in an additional row.
Feel free to leave a comment or to Contact Me for an open discussion!